
FoLiA c'est quoi?
FoLiA est un format de base XML pour la représentation des ressources linguistiques annotées. L'objectif de FoLiA est d'être un format pour stockage et échange des ressources linguistiques, corpora inclus. Nous voulons introduire un seul format riche capable de représenter les différents types d'annotation, à travers un paradigme général. FoLiA n'est pas limité à aucun ensemble d'étiquettes linguistiques, aucune langue ou aucune théorie linguistique spécifique. On laisse toujours ça à l'utilisateur, pour ainsi offrir une flexibilité maximale.
XML est un format hiérarchique. FoLiA en profite en utilisant une structure in-line et hierarchique.
Le but de FoLiA n'est pas d'offir encore un autre format, mais de construire une infrastructure riche et pratique de logiciels et bibliothèques qui utilisent ce format.
Charactéristiques
Les charactéristiques principales de FoLiA sont:
- Paradigme général - On utilise un paradigme général et uniforme, avec le minimum de solutions ad-hoc.
- Expressivité - Le format est très expressif, on peut formuler des annotations de manière très détaillée, mais sans forcer des détails indésirables sur l'utilisateur. FoLiA appuye des annotations alternatives et metadata pour des annotations; comme l'information à propos de l'annotateur, temps de l'annotation, confidence, etc..
- Extensible - Grâce au paradigme uniforme et le fait que le format ne se limite pas à un seul ensemble d'étiquettes linguistiques, FoLiA est bien extensible.
- Formalisé - Le format est formalisé, ça veut dire qu'on peut le valider sur un niveau superficiel, et sur un niveau profond; le niveau profond vérifie aussi les étiquettes.
- Pratique - FoLiA était contruit de manière bottom-up, à côté de ses applications, bibliothèques et convertisseurs. Bien que le format est riche, nous essayons de ne pas le compliquer. L'utilisation et l'apprentissage sont le plus simples possibiles pour faciliter l'adoption du format.
FoLiA combine l'utilisation d'annotation 'in-line' et 'stand-off'. Ce premier est utilisé pour des annotations concernants des mots/termes uniques, alors que l'annotation stand-off est utilisé pour les annotations sur plusieurs termes. Ceci donne à FoLiA la flexibilité et expressivité essentiel pour le soutien de divers types d'annotation linguistique.
Schème du paradigme
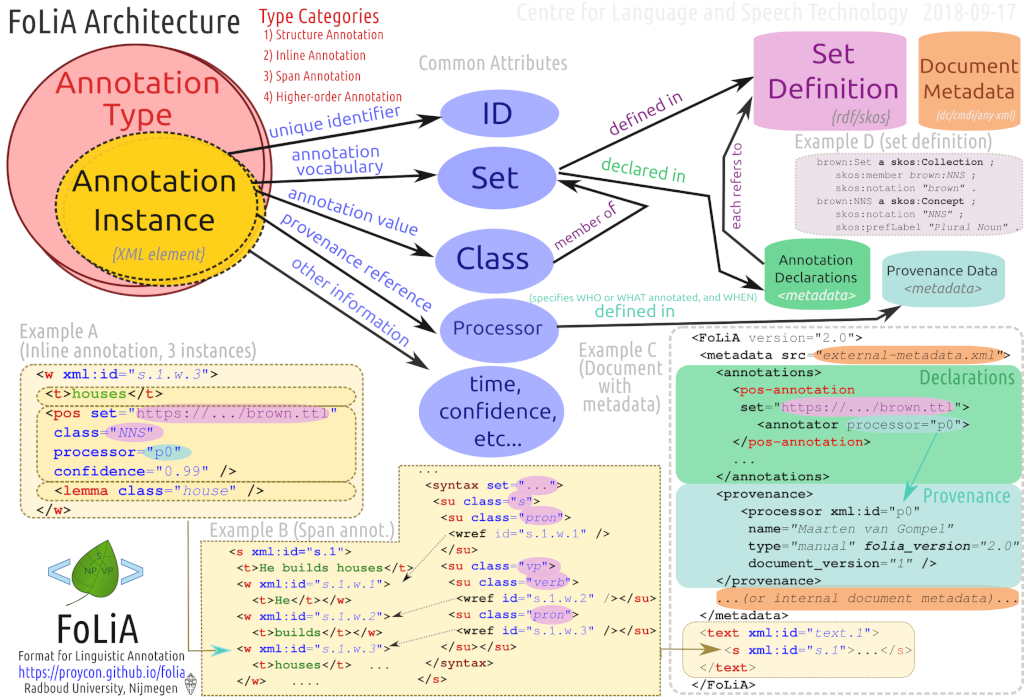
Ressources
Ici vous trouverez la documentation, schéma de validation et des autres ressources pour la dernière version de FoLiA. Consultez la dépôt de FoLiA sur github pour y trouver tous les ressources.
- FoLiA documentation (PDF, en anglais)
- FoLiA dépôt sur github (contient des convertisseurs, schemas, utils, etc)
- FoLiA RelaxNG schéma (pour la validation)
- Exemple d'un document FoLiA (avec visualisation par XSL, consultez la source pour voir l'XML)
Il y a deux bibliothèques pour travailler avec le format FoLiA à partir de vos propres scripts et programmes. Vérifiez fréquemment si votre copie peut être actualisé:
- pynlpl.formats.folia (Bibliothèque python) - par Maarten van Gompel, distribué comme partie de PyNLPl
- Documentation de la bibliothèque (Introduction et reference API)
- Nous vous conseillons d'obtenir pynlpl à travers du Python Package Index ou directement de github, ça garantit que vous avec la version plus récente et que vous la pouvez actualiser facilment: $ sudo pip install pynlpl
- libfolia (Bibliothèque C++) - par Ko van der Sloot, Université de Tilburg.
- Il n'y a pas de documentation encore
- Attention: libfolia est nécessaire pour Frog et ucto.
Il y a aussi un logiciel d'annotation pour FoLiA.
- FLAT: FoLiA Linguistic Annotation Tool - Logiciel d'annotation linguistique pour FoLiA, sur le web
Pour soutien supplémentaire vous pouvez nous écrire à lamasoftware@science.ru.nl.
Publications & Utilisation
FoLiA est utilisé dans divers projects dans les communautés Néerlandaises et Flamandes de linguistique computationnelle. Le plus grand corpus néerlandais, SoNaR, est publié au format FoLiA. On l'utilise aussi dans certains projets de CLARIN. FoLiA a aussi été integré dans software comme ucto, Frog, Valkuil.net.
FoLiA est développé par Maarten van Gompel à l'université de Tilburg et maintenant à l'université Radboud Nijmegen, avec soutien de Antal van den Bosch, Ko van der Sloot, Martin Reynaert et des autres collègues de la communauté universitaire. Si vous utilisez FoLiA, vous pouvez nous citer comme:
- [PDF|BibTex] Maarten van Gompel & Martin Reynaert (2014). FoLiA: A practical XML format for linguistic annotation - a descriptive and comparative study; Computational Linguistics in the Netherlands Journal; 3:63-81; 2013.
- [PDF] Maarten van Gompel (2014). FoLiA: Format for Linguistic Annotation. Documentation Language and Speech Technology Technical Report Series LST-14-01. Radboud University Nijmegen.
- Maarten van Gompel (2012). FoLiA: Format for Linguistic Annotation. Documentation. ILK Technical Report 12-03. Tilburg University
On à aussi quelques présentations:
- [PNG] Maarten van Gompel (2013). Poster: FoLiA: Format for Linguistic Annotation. CLARIN-NL, Utrecht University
- [PDF] Maarten van Gompel (2012). Presentation: FoLiA: Format for Linguistic Annotation. CLIN22. Tilburg University
{kind=link}
FoLiA est logiciel livre et sous license GNU License Publique v3.