
About FoLiA
FoLiA is an XML-based annotation format, suitable for the representation of linguistically annotated language resources. FoLiA’s intended use is as a format for storing and/or exchanging language resources, including corpora. Our aim is to introduce a single rich format that can accomodate a wide variety of linguistic annotation types through a single generalised paradigm. We do not commit to any label set, language or linguistic theory. This is always left to the developer of the language resource, and provides maximum flexibility.
XML is an inherently hierarchic format. FoLiA does justice to this by maximally utilising a hierarchic, inline, setup.
Our aim with FoLiA is not to introduce yet another format, but to build a rich and practical infrastructure around this format. This includes tools, programming libraries, converters, visualisations and annotation environments.
Features
- Generalised paradigm - We use a generalised paradigm, with as few ad-hoc provisions for annotation types as possible.
- Expressivity - The format is highly expressive, annotations can be expressed in great detail and with flexibility to the user’s needs, without forcing unwanted details. Moreover, FoLiA has generalised support for representing annotation alternatives, and annotation metadata such as information on annotator, time of annotation, and annotation confidence.
- Extensible - Due to the generalised paradigm and the fact that the format does not commit to any label set, FoLiA is fairly easily extensible.
- Formalised - The format is formalised, and can be validated on both a shallow and a deep level (the latter including tagset validation), and easily machine parsable, for which tools are provided.
- Practical - FoLiA has been developed in a bottom-up fashion right alongside applications, libraries, and other toolkits and converters. Whilst the format is rich, we try to maintain it as simple and straightforward as possible, minimising the learning curve and making it easy to adopt FoLiA in practical applications.
The FoLiA format makes mixed-use of inline and stand-off annotation. Inline annotation is used for annotations pertaining to single tokens, whilst stand-off annotation in a separate annotation layers is adopted for annotation types that span over multiple tokens. This provides FoLiA with the necessary flexibility and extensibility to deal with various kinds of annotations.
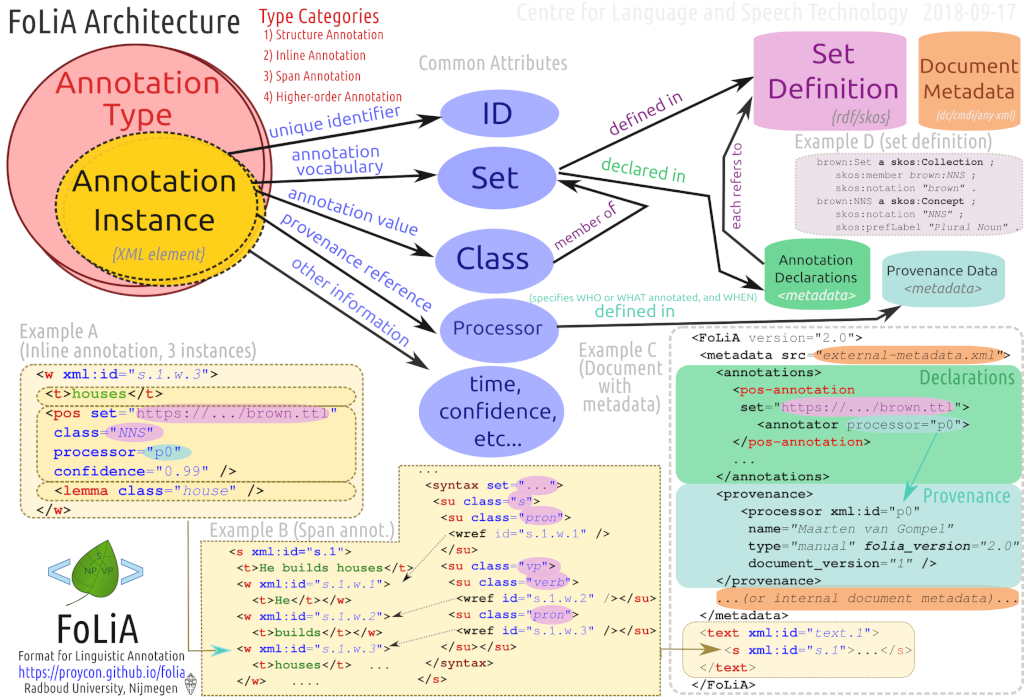
FoLiA Paradigm
Resources
The documentation, validation schema and other resources for the latest FoLiA version can be found below. Consult the FoLiA github repository for all available resources.
- FoLiA documentation
- FoLiA source repository (contains specifications, schemas and examples)
- FoLiA RelaxNG schema (for validation)
Software libraries are available for working with the FoLiA format from within your own scripts and applications. Make sure to check back regularly for updates, as both are still being actively developed.
- FoLiApy (Python 3 library) - by Maarten van Gompel
- Library documentation (Introductory tutorial and API reference)
- We recommend obtaining foliapy through the Python Package Index: $ pip install folia
- libfolia (C++ library) - by Ko van der Sloot, Tilburg University.
- No documentation available yet
- Note: libfolia is a dependency for both Frog and ucto.
- folia-rust (Rust library) - by Maarten van Gompel.
- pynlpl.formats.folia (LEGACY Python library) - by Maarten van Gompel, distributed as part of PyNLPl. Use FoLiApy instead and fall back to this only if you need Python 2.7 support still.
- FoLiA Tools - A set of command-line tools for various operations on FoLiA documents. Contains a validator, convertors and more. Always install and use this to validator your FoLiA documents!
- FoLiA Utilities - Another set of (complementary) command-line tools for various operations on FoLiA documents. Contains a validator, other convertors and more
- FLAT: FoLiA Linguistic Annotation Tool - An elaborate web-based annotation tool for FoLiA.
- Ucto - A multilingual rule-based tokeniser with extensive FoLiA support.
- Frog - An NLP suite for Dutch with extensive FoLiA support.
- PICCL - A set of workflows for corpus building through OCR, post-correction, modernization of historic language and Natural Language Processing.
- Colibri Core - Colibri Core is software to quickly and efficiently count and extract patterns from large corpus data, to extract various statistics on the extracted patterns, and to compute relations between the extracted patterns. (limited FoLiA input support)
- FoLiA Document Server - HTTP webservice backend for serving and annotating FoLiA documents. Serves as the back-end to FLAT.
- Spacy2FoLiA - Adds FoLiA output support to spaCy.
- T-scan - An analysis tool for dutch texts to assess the complexity of the text.
- PaQu - PaQu is a webservice allowing people to analyse dutch text documents and research word relations. (limited FoLiA support)
- BlackLab - A corpus retrieval engine based on Apache Lucene. (limited FoLiA indexing support)
- MTAS - Multi-Tier Annotation Search (limited FoLiA indexing support)
- FoliaParse - Command-line application that converts 'basic' FoLiA + Alpino into syntactically parsed FoLiA (includes 'surfacing')
- FoliaEntity - Named-entity Linker
- ELAN2FoLiA - ELAN-to-FoLiA (EAF-to-FoLiA) converter
- OpenConvert - Text conversion tool (from e.g. Word, HTML, txt) to corpus formats TEI or FoLiA) (limited FoLiA support!)
- CoreNLP2FoLiA - Extend stanford CoreNLP to support exporting FoLiA format.
- NAFFoLiAPy - Library for converting NAF to FoLiA (limited) and FoLiA to NAF (very limited)
- Essay Annotation - Parses Word documents with a specific markup (called essay annotation) into FoLiA XML and back.
For additional support use our Issue tracker or mail lamasoftware@science.ru.nl .
Publications
If you make use of FoLiA in your work, please cite one or more of the following publications. A link to this website is also much appreciated.
- [PDF|BibTex] Maarten van Gompel & Martin Reynaert (2014). FoLiA: A practical XML format for linguistic annotation - a descriptive and comparative study; Computational Linguistics in the Netherlands Journal; 3:63-81; 2013.
- [PDF] Maarten van Gompel, Ko van der Sloot, Martin Reynaert, Antal van den Bosch (2017). FoLiA in Practice: The Infrastructure of a Linguistic Annotation Format. In: CLARIN in the Low Countries. Eds: Jan Odijk and Arjan van Hessen. Pp. 71-81.
- [PDF|HTML] Maarten van Gompel (2019). FoLiA: Format for Linguistic Annotation. Documentation Language and Speech Technology Technical Report Series. Radboud University Nijmegen.
- Maarten van Gompel (2014). FoLiA: Format for Linguistic Annotation. Documentation. Language and Speech Technology Technical Report Series LST-14-01. Radboud University Nijmegen.
- Maarten van Gompel (2012). FoLiA: Format for Linguistic Annotation. Documentation. ILK Technical Report 12-03. Tilburg University
Posters & Presentations
- [PDF] Maarten van Gompel (2018). Poster: FoLiA: Format for Linguistic Annotation. Presented at CLIN28. Nijmegen University
- [PNG] Maarten van Gompel (2013). Poster: FoLiA: Format for Linguistic Annotation. Presented for CLARIN-NL, Utrecht University
- [PDF] Maarten van Gompel (2012). Presentation: FoLiA: Format for Linguistic Annotation. Presented at CLIN22. Tilburg University
{kind=link}
FoLiA is currently used in a wide variety of projects in the Dutch and Flemish Natural Language Processing community. The largest Dutch corpus, SoNaR, is delivered in FoLiA format, and various CLARIN-NL and CLARIAH projects make use of it as well. Support for FoLiA is integrated into various software projects; including but not limited to ucto, Frog, Valkuil.net.
FoLiA was developed by Maarten van Gompel at Tilburg University and now at Radboud University Nijmegen, with input from Antal van den Bosch, Ko van der Sloot, Martin Reynaert and many other people in the academic community.
FoLiA is open-source and all technical resources are licensed under the GNU Public License v3.