
Over FoLiA
FoLiA is een op XML gebaseerd formaat, geschikt voor het representeren van linguïstisch geannoteerde data zoals corpora. FoLiA is bedoeld als een formaat voor het opslaan en uitwisselen van linguïstisch-geannoteerde data. Het doel is om verschillende linguïstische annotaties te ondersteunen in één enkel rijk formaat met een generiek paradigma. We commiteren ons niet aan een bepaalde label set, taal, of linguïstische theorie. Deze keus is altijd aan de ontwikkelaar van de data, en geeft zo maximale flexibiliteit.
XML is een hiërarchisch formaat. FoLiA doet hier recht aan door waar mogelijk een hiërarchische inline aanpak te volgen.
Ons doel met FoLiA is niet om zomaar nóg een ander formaat te introduceren, maar om een rijke en praktische infrastuctuur rondom het formaat te bouwen. Dit omvat diverse soorten software, bibliotheken en conversieprogramma's.
Kenmerken
De hoofdkenmerken van FoLiA zijn:
- Generaliseerd paradigma - We gebruiken een gegeneraliseerd paradigma, met zo min mogelijk ad-hoc oplossingen.
- Expressiviteit - Het formaat is erg expressief. Annotaties kunnen in groot detail opgenomen worden als de gebruiker daar behoefte aan heeft, maar zonder nodeloze details te forceren. Bodendien heeft FoLiA ook ondersteuning voor het representeren van alternatieve annotaties, en annotatie metadata zoals informatie over de annotator, tijd van annotatie, en het vertrouwen in een bepaalde annotatie.
- Uitbreidbaar - Door het generieke paradigma en het feit dat het formaat geen label-sets voorschrijft is FoLiA vrij gemakkelijk uit te breiden.
- Geformaliseerd - Het formaat kan gevalideerd worden op zowel een opperlakkig als een diep niveau (de laatstgenoemde doet ook label-set validatie). Het is makkelijk machine-parseable, waarvoor ook de nodige toepassingen geleverd worden.
- Praktisch - Het FoLiA formaat is op een bottom-up manier ontwikkeld tegelijkertijd met toepassingen, bibliotheken en andere applicaties. Hoewel het formaat erg rijk is, proberen we het zo eenvoudig mogelijk te houden om de leercurve te beperken en het makkelijker te maken om FoLiA in praktische toepassingen en datasets te gebruiken.
FoLiA maakt gebruik van zowel inline als stand-off annotatie. Inline annotatie wordt gebruikt voor annotaties behorende bij tokens of onder andere structuurelementen. Stand-off annotatie wordt gebruikt voor annotaties die over een spanne van meerde tokens rijken en worden in een speciale annotatielaag opgenomen die op verschillende niveaus ingebed kan worden. Dit geeft FoLiA de nodige flexibiliteit om met verschillende soorten annotaties om te kunnen gaan.
FoLiA Paradigma
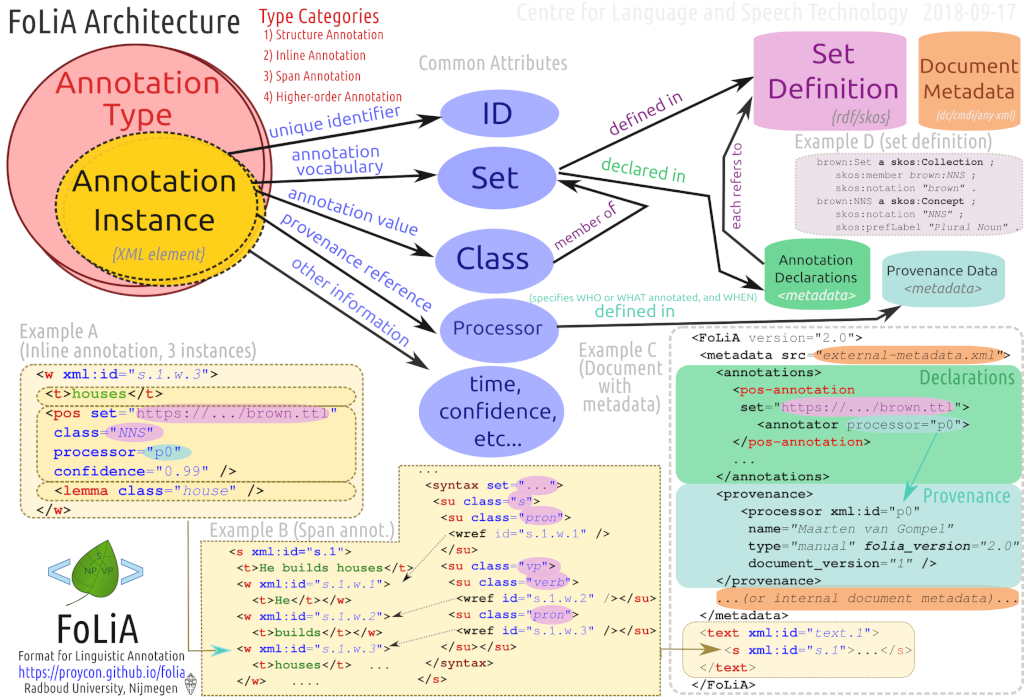
Documentatie, implementaties en andere materialen
Hieronder zijn links naar onder andere de documentatie, het validatieschema, links naar implementaties en andere zaken te vinden. Zie ook de FoLiA github repository voor alle beschikbare tools en code.
- FoLiA documentatie (PDF, engelstalig)
- FoLiA broncode op github (bevat converterscripts, schemas, XSL stylesheets, etc)
- FoLiA RelaxNG schema (voor validatie)
- Voorbeeld FoLiA-document (met browservisualisatie dmv XSL, bekijk de broncode voor XML)
Twee software-bibliotheken zijn beschikbaar om met het FoLiA te werken vanuit uw eigen scripts en applicaties. Kijk geregeld terug voor updates, want beide zijn volop in ontwikkeling.
- pynlpl.formats.folia (Python library) - door Maarten van Gompel, gedistribueerd als deel van PyNLPl
- Bibliotheek documentatie (tutorial en API reference, engelstalig)
- We bevelen aan op pynlpl te verkrijgen middels de Python Package Index of rechtstreeks van github, dit zorgt ervoor dat u altijd de laatste versie heeft: $ sudo pip install pynlpl
- libfolia (C++ library) - door Ko van der Sloot, Universiteit Tilburg
- Nog geen documentatie beschikbaar
- Let op: libfolia is vereist voor zowel Frog als ucto!
Er is ook een web-gebaseerde annotatieomgeving beschikbaar om FoLiA bestanden te creeëren en bewerken.
- FLAT: FoLiA Linguistische Annotatieomgeving - Web-gebaseerde annotatieomgeving voor FoLiA
Voor verdere ondersteuning kunt onze Issue tracker gebruiken of mailen naar lamasoftware@science.ru.nl .
Publicaties
Als je gebruikt maakt van FoLiA, citeer dan één van de volgende publicaties:
- [PDF|BibTex] Maarten van Gompel & Martin Reynaert (2014). FoLiA: A practical XML format for linguistic annotation - a descriptive and comparative study; Computational Linguistics in the Netherlands Journal; 3:63-81; 2013.
- [PDF] Maarten van Gompel (2014). FoLiA: Format for Linguistic Annotation. Documentation Language and Speech Technology Technical Report Series LST-14-01. Radboud University Nijmegen.
- Maarten van Gompel (2012). FoLiA: Format for Linguistic Annotation. Documentation. ILK Technical Report 12-03. Tilburg University
Posters & Presentaties
- [PNG] Maarten van Gompel (2013). Poster: FoLiA: Format for Linguistic Annotation. Gepresenteerd voor CLARIN-NL, Utrecht University
- [PDF] Maarten van Gompel (2012). Presentation: FoLiA: Format for Linguistic Annotation. Gepresenteerd tijdens CLIN22. Tilburg University
{kind=link}
FoLiA wordt momenteel door veel verschillende projecten in de Nederlandse en Vlaamse Computerlinguïstiek-gemeenschap gebruikt. Het grootste Nederlandstalige corpus, SoNaR, is in FoLiA beschikbaar, en verschillende CLARIN projekten maken ook gebruik van FoLiA. Verder is FoLiA-ondersteuning geïntegreerd in verschillende software-pakketten, waaronder ucto, Frog en Valkuil.net.
FoLiA s ontwikkeld door Maarten van Gompel, eerst aan de Universiteit van Tilburg en daarna aan de Radboud Universiteit Nijmegen, met bijdragen van Antal van den Bosch, Ko van der Sloot, Martin Reynaert en anderen.
FoLiA is open-source en beschikbaar onder de termen van de GNU Publieke Licentie v3.